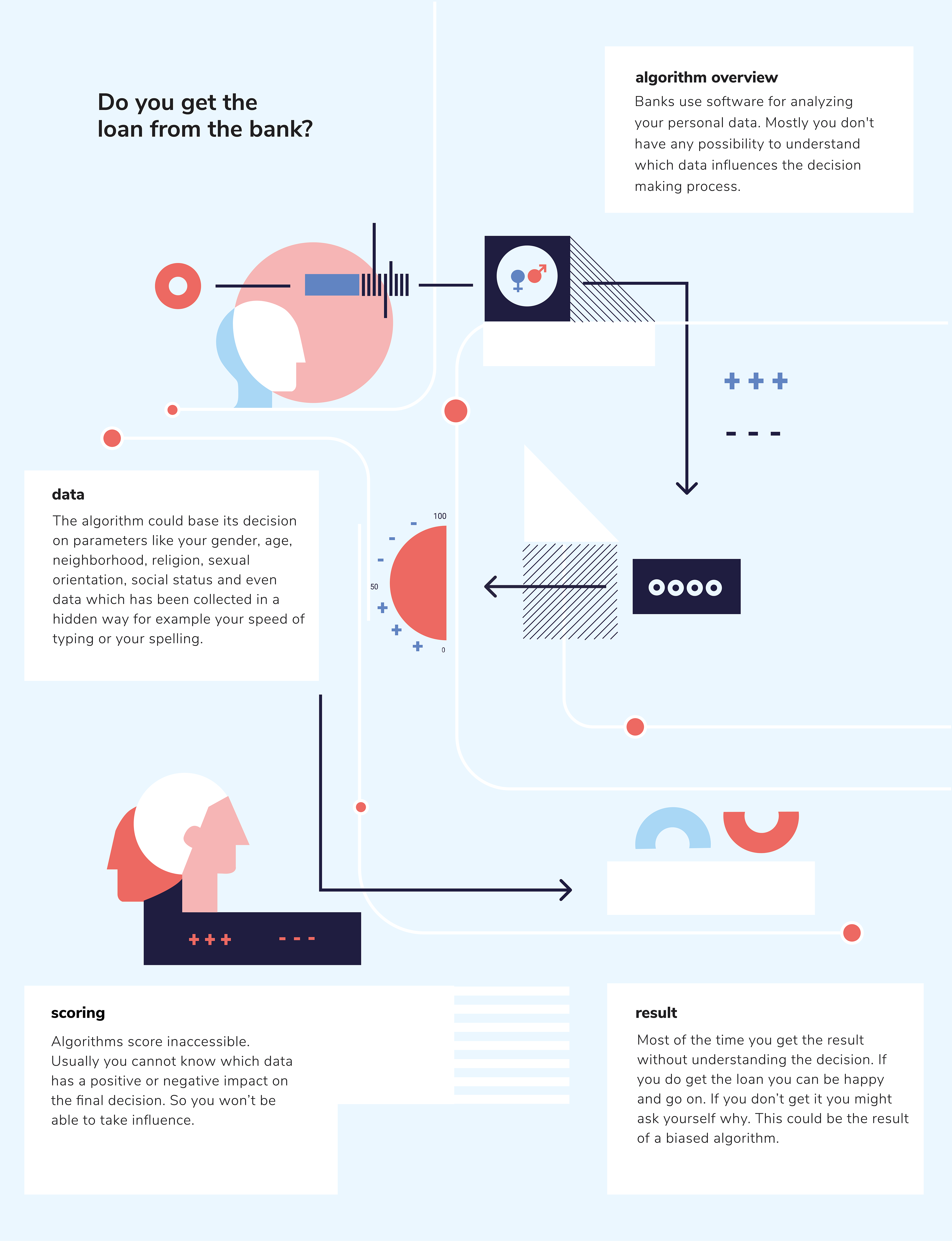
We have become so used to the invisible hands of Google, Facebook and Amazon that we feed them with data every day. As a result, algorithms make our everyday life easier, no matter whether we get a suitable film suggested on Netflix, the best playlist displayed at Spotify, avoid traffic jams with GPS navigation or get inspired for search entries with Google’s autocomplete.
But algorithms do much more than just satisfy our everyday needs. They got indispensable in many areas of society. They can diagnose diseases before the first signs of symptoms, according to studies traffic deaths can be reduced by up to 90 percent and their calculations can ensure that production will be more resource-efficient and environmentally friendly.
The great social responsibility given to algorithms leads to the following question: what happens when algorithms make mistakes?